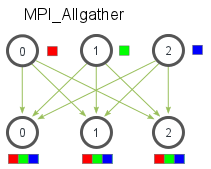
Hello world from processor yiqi-OMEN-by-HP, rank 0 out of 4 processors Hello world from processor yiqi-OMEN-by-HP, rank 1 out of 4 processors Hello world from processor yiqi-OMEN-by-HP, rank 2 out of 4 processors Hello world from processor yiqi-OMEN-by-HP, rank 3 out of 4 processors
MPI的发送和接收简介
MPI的发送和接收方法是按以下方式进行的:开始的时候,A 进程决定要发送一些消息给 B 进程。A 进程就会把需要发送给 B 进程的所有数据打包好,放到一个缓存里面。因为所有数据会被打包到一个大的信息里面,因此缓存常常会被比作 信封 。数据打包进缓存之后,通信设备(通常是网络)就需要负责把信息传递到正确的地方。这个正确的地方也就是根据特定rank确定的那个进程。
尽管数据已经被送达到 B 了,但是进程 B 依然需要确认它想要接收 A 的数据。一旦它确定了这点,数据就被传输成功了。进程 A 会接收到数据传递成功的信息,然后去干其他事情。
有时候 A 需要传递很多不同的消息给 B。为了让 B 能比较方便地区分不同的消息,MPI运行发送者和接受者额外地指定一些信息 ID (正式名称是 标签 , tags )。当 B 只要求接收某种特定标签的信息的时候,其他的不是这个标签的信息会先被缓存起来,等到 B 需要的时候才会给 B 。
MPI发送和接收方法的定义:
1 2 3 4 5 6 7 8
MPI_Send( void* data, int count, MPI_Datatype datatype, int destination, int tag, MPI_Comm communicator )
1 2 3 4 5 6 7 8 9
MPI_Recv( void* data, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm communicator, MPI_Status* status )
MPI_Send(numbers, number_amount, MPI_INT, 1, 0, MPI_COMM_WORLD); printf("0 sent %d numbers to 1\n", number_amount); } elseif (world_rank == 1) { MPI_Status status; // Probe for an incoming message from process zero MPI_Probe(0, 0, MPI_COMM_WORLD, &status); // When probe returns, the status object has the size and other // attributes of the incoming message. Get the message size MPI_Get_count(&status, MPI_INT, &number_amount);
for (i = 0; i < num_trials; i++) { // Time my_bcast // Synchronize before starting timing MPI_Barrier(MPI_COMM_WORLD); total_my_bcast_time -= MPI_Wtime(); my_bcast(data, num_elements, MPI_INT, 0, MPI_COMM_WORLD); // Synchronize again before obtaining final time MPI_Barrier(MPI_COMM_WORLD); total_my_bcast_time += MPI_Wtime();
Avg of all elements from 0 is 0.483204 Avg of all elements from 1 is 0.483204 Avg of all elements from 2 is 0.483204 Avg of all elements from 3 is 0.483204
// Sum the numbers locally float local_sum = 0; int i; for (i = 0; i < num_elements_per_proc; i++) { local_sum += rand_nums[i]; }
// Print the random numbers on each process printf("Local sum for process %d - %f, avg = %f\n", world_rank, local_sum, local_sum / num_elements_per_proc);
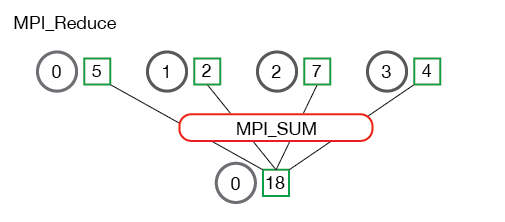
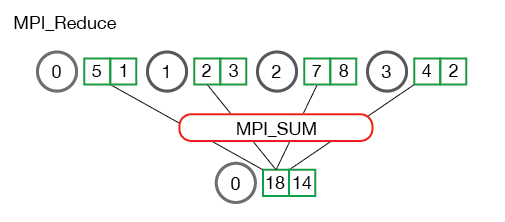
// Reduce all of the local sums into the global sum float global_sum; MPI_Reduce(&local_sum, &global_sum, 1, MPI_FLOAT, MPI_SUM, 0, MPI_COMM_WORLD);
// Print the result if (world_rank == 0) { printf("Total sum = %f, avg = %f\n", global_sum, global_sum / (world_size * num_elements_per_proc)); }
只有根进城的global_sum有效
输出结果如下:
1 2 3 4 5
Local sum for process 0 - 133.853, avg = 0.522864 Local sum for process 1 - 131.135, avg = 0.512248 Local sum for process 3 - 125.31, avg = 0.489492 Local sum for process 2 - 127.639, avg = 0.49859 Total sum = 517.938, avg = 0.505798
// Sum the numbers locally float local_sum = 0; int i; for (i = 0; i < num_elements_per_proc; i++) { local_sum += rand_nums[i]; }
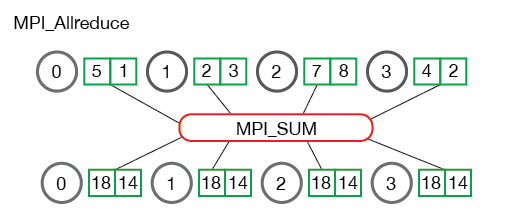
// Reduce all of the local sums into the global sum in order to calculate the mean float global_sum; MPI_Allreduce(&local_sum, &global_sum, 1, MPI_FLOAT, MPI_SUM, MPI_COMM_WORLD); float mean = global_sum / (num_elements_per_proc * world_size);
// Compute the local sum of the squared differences from the mean float local_sq_diff = 0; for (i = 0; i < num_elements_per_proc; i++) { local_sq_diff += (rand_nums[i] - mean) * (rand_nums[i] - mean); }
// Reduce the global sum of the squared differences to the root process and print off the answer float global_sq_diff; MPI_Reduce(&local_sq_diff, &global_sq_diff, 1, MPI_FLOAT, MPI_SUM, 0, MPI_COMM_WORLD);
// The standard deviation is the square root of the mean of the squared differences. if (world_rank == 0) { float stddev = sqrt(global_sq_diff / (num_elements_per_proc * world_size)); printf("Mean - %f, Standard deviation = %f\n", mean, stddev); }
0 sent and incremented ping_pong_count 1 to 1 0 received ping_pong_count 2 from 1 0 sent and incremented ping_pong_count 3 to 1 0 received ping_pong_count 4 from 1 0 sent and incremented ping_pong_count 5 to 1 0 received ping_pong_count 6 from 1 0 sent and incremented ping_pong_count 7 to 1 0 received ping_pong_count 8 from 1 0 sent and incremented ping_pong_count 9 to 1 0 received ping_pong_count 10 from 1 1 received ping_pong_count 1 from 0 1 sent and incremented ping_pong_count 2 to 0 1 received ping_pong_count 3 from 0 1 sent and incremented ping_pong_count 4 to 0 1 received ping_pong_count 5 from 0 1 sent and incremented ping_pong_count 6 to 0 1 received ping_pong_count 7 from 0 1 sent and incremented ping_pong_count 8 to 0 1 received ping_pong_count 9 from 0 1 sent and incremented ping_pong_count 10 to 0
Process 1 received token -1 from process0 Process 2 received token -1 from process1 Process 3 received token -1 from process2 Process 0 received token -1 from process3