CUDA流概述 一个CUDA流指的是由主机发出的在一个设备中执行的CUDA操作(即和CUDA有关的操作,如主机-设备数据传输和核函数执行)序列。
任何CUDA操作都存在于某个CUDA流中,要么是默认流(default stream,也称为空流,null stream),要么是明确指定的非空流。
非默认的CUDA流是在主机端产生与销毁的。一个CUDA流由类型为cudaStream_t的变量表示,它可由如下运行时API函数产生和销毁:
1 2 cudaError_t cudaStreamCreate (cudaStream_t*) ;cudaError_t cudaStreamDestroy (cudaStream_t) ;
没错,产生时用指针,销毁时用变量
为了检查一个CUDA流中的所有操作是否都在设备中执行完毕,CUDA运行时API提供了如下两个函数:
1 2 cudaError_t cudaStreamSynchronize (cudaStream_t stream) ;cudaError_t cudaStreamQuery (cudaStream_t stream) ;
cudaStreamSynchronize()会强制阻塞主机,直到CUDA流stream中的所有操作都执行完毕。函数cudaStreamQuery()不会阻塞主机,只是检查CUDA流stream中的所有操作是否都执行完毕。若是,返回cudaSuccess,否则返回cudaErrorReady。
在默认流中重叠主机和设备计算 以数组相加举例:
1 2 3 4 cudaMemcpy (d_x, h_x, M, cudaMemcpyHostToDevice);cudaMemcpy (d_y, h_y, M, cudaMemcpyHostToDevice);sum<<<grid_size, block_size>>>(d_x, d_y, d_z, N); cudaMemcpy (h_z, d_z, M, cudaMemcpyDeviceToHost);
从主机角度看,数据传输是同步的(阻塞的),即要等待cudaMemcpy(d_x, h_x, M, cudaMemcpyHostToDevice)执行完再往前走。
核函数的启动是异步的(非阻塞的),即主机发出命令sum<<<grid_size, block_size>>>(d_x, d_y, d_z, N)之后不会等待该命令执行完毕,而会立刻得到程序的控制权。
紧接着主机发出cudaMemcpy(h_z, d_z, M, cudaMemcpyDeviceToHost),该命令不会被立即执行,而必须等待前一个CUDA操作(即核函数的调用)执行完毕才会开始执行。
由此可知,主机在发出核函数调用的命令之后,会立刻发出下一个命令 。在上面的例子中,下一个命令是进行数据传输,但从设备的角度来看必须等待核函数执行完毕。如果下—个命令是主机中的某个计算任务,那么主机就会在设备执行核函数的同时去进行一些计算 。这样,主机和设备就可以同时进行计算。设备完全不知道在它执行核函数时,主机偷偷地做了些计算。
例如下面的代码(完整代码见 host_kernel.cu ):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 void cpu_sum (const real *x, const real *y, real *z, const int N_host) for (int n = 0 ; n < N_host; ++n) { z[n] = x[n] + y[n]; } } void __global__ gpu_sum (const real *x, const real *y, real *z) const int n = blockDim.x * blockIdx.x + threadIdx.x; if (n < N) { z[n] = x[n] + y[n]; } } void timing ( const real *h_x, const real *h_y, real *h_z, const real *d_x, const real *d_y, real *d_z, const int ratio, bool overlap ) if (!overlap) { cpu_sum (h_x, h_y, h_z, N / ratio); } gpu_sum<<<grid_size, block_size>>>(d_x, d_y, d_z); if (overlap) { cpu_sum (h_x, h_y, h_z, N / ratio); } }
选择overlap为真时,将在调用核函数之后调用一个主机端函数,从而达到并发执行的效果。
用非默认CUDA流重叠多个核函数执行 同一个CUDA流中的CUDA操作在设备中是顺序执行的,故同一个CUDA流中的核函数也必须在设备中顺序执行。要实现多个核函数之间的并行必须使用多个CUDA流。
函数执行配置中的流参数 调用一个名为my_kernel的核函数有如下三种方式:
1 2 3 my_kernel<<<N_grid, N_block>>>(函数参数); my_kernel<<<N_grid, N_block, N_shared>>>(函数参数); my_kernel<<<N_grid, N_block, N_shared, stream_id>>>(函数参数);
前两种方式属于在默认流中不使用和使用动态共享内存的方式。第三种调用方式说明核函数在编号为stream_id的CUDA流中执行,并且使用了N_shared动态共享内存。如果不想使用动态共享内存,调用方式为
1 my_kernel<<<N_grid, N_block, 0 , stream_id>>>(函数参数);
叠多个核函数的例子 例如下面的代码(完整代码见 kernel_kernel.cu )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 cudaStream_t streams[MAX_NUM_STREAMS]; for (int n = 0 ; n < MAX_NUM_STREAMS; ++n) { CHECK (cudaStreamCreate (&(streams[n]))); } for (int num = 1 ; num <= MAX_NUM_STREAMS; ++num) { timing (d_x, d_y, d_z, num); } for (int n = 0 ; n < MAX_NUM_STREAMS; ++n) { CHECK (cudaStreamDestroy (streams[n])); } void timing (const real *d_x, const real *d_y, real *d_z, const int num) for (int n = 0 ; n < num; ++n) { int offset = n * N1; add<<<grid_size, block_size, 0 , streams[n]>>>(d_x + offset, d_y + offset, d_z + offset); } }
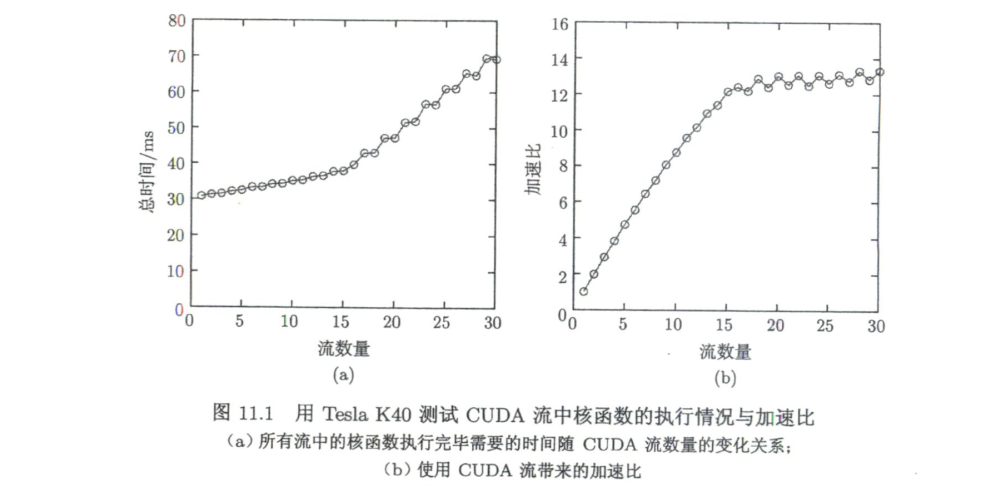
这个程序比较了随着CUDA流增多(数据量也成倍增多)执行时间的变化情况。一开始执行时间并没有明显增加,说明使用同样的时间可以处理更多的数据。
Tesla K40有15个SM,作者使用Tesla K40测试时,在流数量达到15时,加速就不是很明显,似乎说明一个核函数占用了一个SM,如下图所示:
上面说明制约GPU加速的是计算资源,另外还有一个因素是单个GPU中能够并发执行的核函数个数上限。不同计算能力这个上限不同,比如计算能力7.5对应的是128。K40计算能力3.5,最大核函数并发数目为32,将上述程序的单个核函数线程束由1024降为128,测试结果如下:
用非默认CUDA流重叠核函数的执行与数据传递 不可分页主机内存与异步的数据传输函数 要实现核函数执行与数据传输的并发(重叠),必须让这两个操作处于不同的非默认流,而且数据传输必须使用cudaMemcpy()函数的异步版本,即cudaMemcpyAsync()函数。异步传输由GPU中的DMA(direct memory access)直接实现,不需要主机参与。异步传输函数原型为:
1 2 3 4 5 6 7 cudaError_t cudaMemcpyAsync ( void *dist, const void *src, size_t count, enum cudaMemcpyKind kind, cudaStream_t stream )
在使用异步的数据传输函数时,需要将主机内存定义为不可分页内存(non-pageable memory)或者固定内存(pinned memory)。操作系统有权在一个程序运行期间改变程序中使用的可分页主机内存的物理地址。相反,若主机中的内存声明为不可分页内存,则在程序运行期间其物理地址将保持不变。如果将可分页内存传给cudaMemcpyAsync()函数,则会导致同步传输,达不到重叠核函数执行与数据传输的效果。
不可分页主机内存的分配可以由以下两个CUDA运行时API函数中的任何
1 2 cudaError_t cudaMallocHost (void ** ptr, sizt_t , size) ;cudaError_t cudaHostAlloc (void ** ptr, size_t size, size_t flags) ;
若函数cudaHostAlloc()的第三个参数取默认值cudaHostAllocDefault则以上两个函数完全等价,这里不讨论取其他值的用法。
以上分配的主机内存由如下函数释放:
1 cudaError_t cudaFreeHost (void * ptr) ;
重叠核函数执行与数据传输的例子 我们将主机向设备传输数据记为H2D,核函数计算记为KER,设备传输数据到主机记为D2H。一个可行的并发方案是,将数据分为多份,并发传输数据并计算。比如将数据分为两份,使用两个CUDA流:
1 2 Stream 1: H2D -> KER -> D2H Stream 2: H2D -> KER -> D2H
如果H2D、KER和D2H耗时相同,那么我们相当于把总共6步的操作变成了4步,加速比为1.5。类似的,使用4个流时,加速比为2。理论上最大加速比为3(三步耗时相同的情况下)。
代码示例如下(完整代码见 kernel_transfer.cu ):
1 2 3 4 5 6 7 8 9 10 11 12 13 void timing (const real *h_x, const real *h_y, real *h_z, real *d_x, real *d_y, real *d_z, const int num) int offset = i * N1; CHECK (cudaMemcpyAsync (d_x + offset, h_x + offset, M1, cudaMemcpyHostToDevice, streams[i])); CHECK (cudaMemcpyAsync (d_y + offset, h_y + offset, M1, cudaMemcpyHostToDevice, streams[i])); int block_size = 128 ; int grid_size = (N1 - 1 ) / block_size + 1 ; add<<<grid_size, block_size, 0 , streams[i]>>>(d_x + offset, d_y + offset, d_z + offset, N1); CHECK (cudaMemcpyAsync (h_z + offset, d_z + offset, M1, cudaMemcpyDeviceToHost, streams[i])); }
作者的测试结果如下:
统一内存简介 统一内存是一种自动分配位置的,主机和设备都可访问的内存。从开普勒架构开始得到支持,开普勒和麦克斯韦架构的统一内存称为第一代统一内存,从帕斯卡架构开始的统一内存称为第二代统一内存。目前Windows平台对统一内存的支持不完善,Linux平台支持较好。使用统一内存的话,可对显存进行超量分配,超出显存的部分可能存放在主机上。
统一内存的使用方法 动态统一内存 统一内存需要在主机端定义或分配,使用CUDA运行时API函数:
1 2 3 4 5 cudaError_t cudaMallocManaged ( void **devPtr, size_t size, unsigned flages = 0 )
相比cudaMalloc(),该函数多了一个可选参数flags,默认值为cudaMemAttachGlobal
统一内存释放依然使用cudaFree()
以数组相加为例,主函数代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 int main (void ) const int N = 100000000 ; const int M = sizeof (double ) * N; double *x, *y, *z; CHECK (cudaMallocManaged ((void **)&x, M)); CHECK (cudaMallocManaged ((void **)&y, M)); CHECK (cudaMallocManaged ((void **)&z, M)); for (int n = 0 ; n < N; ++n) { x[n] = a; y[n] = b; } const int block_size = 128 ; const int grid_size = N / block_size; add<<<grid_size, block_size>>>(x, y, z); CHECK (cudaDeviceSynchronize ()); check (z, N); CHECK (cudaFree (x)); CHECK (cudaFree (y)); CHECK (cudaFree (z)); return 0 ; }
静态统一内存 要定义静态统一内存,只需要在修饰符__device__的基础上再加上修饰符__managed__即可。这样的变量要在任何函数外部定义,本文件可见。例如:
1 2 3 4 5 6 7 8 9 10 __device__ __managed__ int ret[1000 ]; __global__ void AplusB (int a, int b) ;int main () AplusB<<<1 , 1000 >>>(10 , 1000 ); cudaDeviceSynchronize (); for (int i = 0 ; i < 1000 ; i++) printf ("%d: A + B = %d\n" , i ret[i]); return 0 ; }
使用统一内存申请超量内存 该功能无法在Windows平台上使用
测试1 对于程序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include "error.cuh" #include <stdio.h> #include <stdint.h> const int N = 30 ;int main (void ) for (int n = 1 ; n <= N; ++n) { const size_t size = size_t (n) * 1024 * 1024 * 1024 ; uint64_t *x; #ifdef UNIFIED CHECK (cudaMallocManaged (&x, size)); CHECK (cudaFree (x)); printf ("Allocated %d GB unified memory without touch.\n" , n); #else CHECK (cudaMalloc (&x, size)); CHECK (cudaFree (x)); printf ("Allocate %d GB device memory.\n" , n); #endif } return 0 ; }
不使用统一内存的情况下,输出如下:
1 2 3 4 5 6 7 8 9 10 11 12 Allocate 1 GB device memory. Allocate 2 GB device memory. Allocate 3 GB device memory. Allocate 4 GB device memory. Allocate 5 GB device memory. Allocate 6 GB device memory. Allocate 7 GB device memory. CUDA Error: File: tutorials/over_subscription1.cu Line: 18 Error code: 2 Error text: out of memory
因为显存只有8G,所以分配超过8G显存就会报错。使用统一内存的情况下,输出如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Allocated 1 GB unified memory without touch. Allocated 2 GB unified memory without touch. Allocated 3 GB unified memory without touch. Allocated 4 GB unified memory without touch. Allocated 5 GB unified memory without touch. Allocated 6 GB unified memory without touch. Allocated 7 GB unified memory without touch. Allocated 8 GB unified memory without touch. Allocated 9 GB unified memory without touch. Allocated 10 GB unified memory without touch. Allocated 11 GB unified memory without touch. Allocated 12 GB unified memory without touch. Allocated 13 GB unified memory without touch. Allocated 14 GB unified memory without touch. Allocated 15 GB unified memory without touch. Allocated 16 GB unified memory without touch. Allocated 17 GB unified memory without touch. Allocated 18 GB unified memory without touch. Allocated 19 GB unified memory without touch. Allocated 20 GB unified memory without touch. Allocated 21 GB unified memory without touch. Allocated 22 GB unified memory without touch. Allocated 23 GB unified memory without touch. Allocated 24 GB unified memory without touch. Allocated 25 GB unified memory without touch. Allocated 26 GB unified memory without touch. Allocated 27 GB unified memory without touch. Allocated 28 GB unified memory without touch. Allocated 29 GB unified memory without touch. Allocated 30 GB unified memory without touch.
虽然内存加显存加起来不到30GB,但显示可以分配30GB,是因为cudaMallocManaged()只是预定了一段地址空间,而统一内存的实际分配发生在主机或设备第一次访问预留的内存时。
测试2 这次使用核函数进行实际分配,测试程序如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include "error.cuh" #include <stdio.h> #include <stdint.h> const int N = 30 ;__global__ void gpu_touch (uint64_t *x, const size_t size) { const size_t i = blockIdx.x * blockDim.x + threadIdx.x; if (i < size) { x[i] = 0 ; } } int main (void ) for (int n = 1 ; n <= N; ++n) { const size_t memory_size = size_t (n) * 1024 * 1024 * 1024 ; const size_t data_size = memory_size / sizeof (uint64_t ); uint64_t *x; CHECK (cudaMallocManaged (&x, memory_size)); gpu_touch<<<(data_size - 1 ) / 1028 + 1 , 1024 >>>(x, data_size); CHECK (cudaGetLastError ()); CHECK (cudaDeviceSynchronize ()); CHECK (cudaFree (x)); printf ("Allocated %d GB unified memory with GPU touch.\n" , n); } return 0 ; }
输出如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 Allocated 1 GB unified memory with GPU touch. Allocated 2 GB unified memory with GPU touch. Allocated 3 GB unified memory with GPU touch. Allocated 4 GB unified memory with GPU touch. Allocated 5 GB unified memory with GPU touch. Allocated 6 GB unified memory with GPU touch. Allocated 7 GB unified memory with GPU touch. Allocated 8 GB unified memory with GPU touch. Allocated 9 GB unified memory with GPU touch. Allocated 10 GB unified memory with GPU touch. Allocated 11 GB unified memory with GPU touch. Allocated 12 GB unified memory with GPU touch. Allocated 13 GB unified memory with GPU touch. Allocated 14 GB unified memory with GPU touch. Allocated 15 GB unified memory with GPU touch. Allocated 16 GB unified memory with GPU touch. Allocated 17 GB unified memory with GPU touch. CUDA Error: File: tutorials/over_subscription2.cu Line: 26 Error code: 700 Error text: an illegal memory access was encountered
当实际分配的内存超出容量时就报错了。
测试3 这次使用主机函数进行实际分配,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include "error.cuh" #include <stdio.h> #include <stdint.h> const int N = 30 ;void cpu_touch (uint64_t *x, size_t size) for (size_t i = 0 ; i < size / sizeof (uint64_t ); i++) { x[i] = 0 ; } } int main (void ) for (int n = 1 ; n <= N; ++n) { size_t size = size_t (n) * 1024 * 1024 * 1024 ; uint64_t *x; CHECK (cudaMallocManaged (&x, size)); cpu_touch (x, size); CHECK (cudaFree (x)); printf ("Allocated %d GB unified memory with CPU touch.\n" , n); } return 0 ; }
输出如下:
1 2 3 4 5 6 7 8 9 10 Allocated 1 GB unified memory with CPU touch. Allocated 2 GB unified memory with CPU touch. Allocated 3 GB unified memory with CPU touch. Allocated 4 GB unified memory with CPU touch. Allocated 5 GB unified memory with CPU touch. Allocated 6 GB unified memory with CPU touch. Allocated 7 GB unified memory with CPU touch. Allocated 8 GB unified memory with CPU touch. Allocated 9 GB unified memory with CPU touch. Allocated 10 GB unified memory with CPU touch.
这里只分配了10GB,说明使用主机分配内存的话,不会自动使用设备内存。
优化使用统一内存的程序 CUDA的统一内存机制可以部分地自动做到数据与处理器接近,但很多情况下需要手动给编译器一些提示,如使用运行时API函数cudaMemAdvise()和cudaMemPrefetchAsync(),这里只讲后者
函数cudaMemPrefetchAsync()的原型为:
1 2 3 4 5 6 cudaError_t cudaMemPrefetchAsync ( const void *devPtr, size_t count, int dstDevice, cudaStream_t strem )
示例程序如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 int main (void ) int device_id = 0 ; CHECK (cudaGetDevice (&device_id)); const int N = 100000000 ; const int M = sizeof (double ) * N; double *x, *y, *z; CHECK (cudaMallocManaged ((void **)&x, M)); CHECK (cudaMallocManaged ((void **)&y, M)); CHECK (cudaMallocManaged ((void **)&z, M)); for (int n = 0 ; n < N; ++n) { x[n] = a; y[n] = b; } const int block_size = 128 ; const int grid_size = N / block_size; CHECK (cudaMemPrefetchAsync (x, M, device_id, NULL )); CHECK (cudaMemPrefetchAsync (y, M, device_id, NULL )); CHECK (cudaMemPrefetchAsync (z, M, device_id, NULL )); add<<<grid_size, block_size>>>(x, y, z); CHECK (cudaMemPrefetchAsync (z, M, cudaCpuDeviceId, NULL )); CHECK (cudaDeviceSynchronize ()); check (z, N); CHECK (cudaFree (x)); CHECK (cudaFree (y)); CHECK (cudaFree (z)); return 0 ; }