CUDA编程02: CUDA内存组织
CUDA内存组织
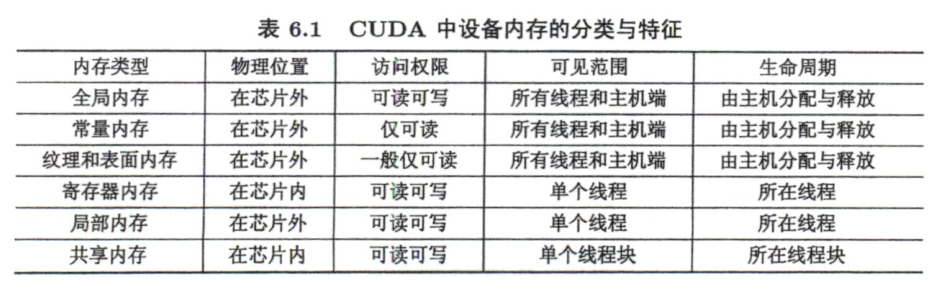
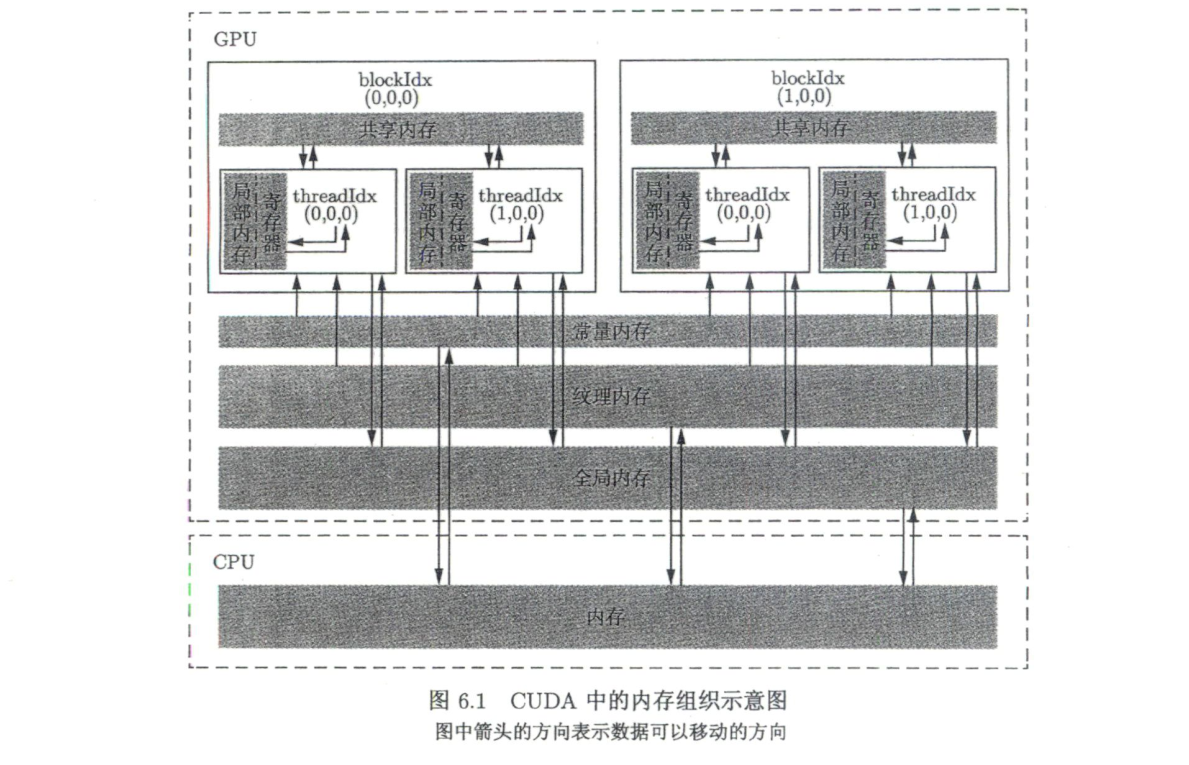
CUDA中不同类型的内存
全局内存
对所有线程开放访问,生命周期从cudaMalloc()开始到cudaFree()结束。
在CUDA中也允许定义静态全局变量,在所有主机与设备函数外定义。定义方法:
1 | __device__ T x; // 单个变量 |
主机不可直接访问CUDA静态全局变量,需要通过cudaMemcpyToSymbol()和cudaMemcpyFromSymbol在CUDA静态全局内存与主机内存之间传递数据。这两个函数原型为
1 | cudaError_t cudaMemcpyToSymbol ( |
1 | cudaError_t cudaMemcpyFromSymbol ( |
- 这两个函数的参数
symbol可以是静态全局内存变量的变量名, 也可以是下面要介绍的常量内存变量的变量名
示例代码如下:
1 |
|
输出结果:
1 | d_x = 1, d_y[0] = 11, d_y[1] = 21. |
常量内存
常量内存是有常量缓存的全局内存,仅有64KB,生命周期与全局内存一样。仅可读不可写,访问速度比全局内存高(前提是一个线程束中的线程(一个线程块中相邻的32个线程)要读取相同的内存数据)
函数参数通过值传递时就是使用的常量内存,另外也可以传递结构体(传值还是传指针?)
纹理内存和表面内存
类似于常量内存,也是一种具有缓存的全局内存,一般仅可读(表面内存也可写),但容量更大,使用方式也不同。
将某些只读的全局内存数据使用__ldg()修饰可以达到利用纹理内存的目的
1 | T __ldg(const T* address); |
对帕斯卡架构和更高的架构来说,全局内存的读取在默认情况下就利用了
__ldg()函数
寄存器
在核函数中定义的不加任何限定符的变量一般来说就存放于寄存器中。核函数中定义的不加任何限定符的数组有可能存放于寄存器中,但也有可能存放于局部内存中。寄存器变量仅对一个线程可见。
局部内存
寄存器中放不下的变量,以及索引值不能在编译时就确定的数组,都有可能放在局部内存中,这种判断是由编译器自动做的。虽然局部内存在用法上类似于寄存器,但从硬件来看,局部内存只是全局内存的一部分。所以,局部内存的延迟也很高。每个线程最多能使用高达512KB的局部内存,但使用过多会降低程序的性能。
共享内存
共享内存和寄存器类似,存在于芯片上,具有仅次于寄存器的读写速度,数量也有限。不同于寄存器的是,共享内存对整个线程块可见,其生命周期也与整个线程块一致。
L1和L2缓存
对某些架构来说,还可以针对单个核函数或者整个程序改变L1缓存和共享内存的比例。本书不涉及。
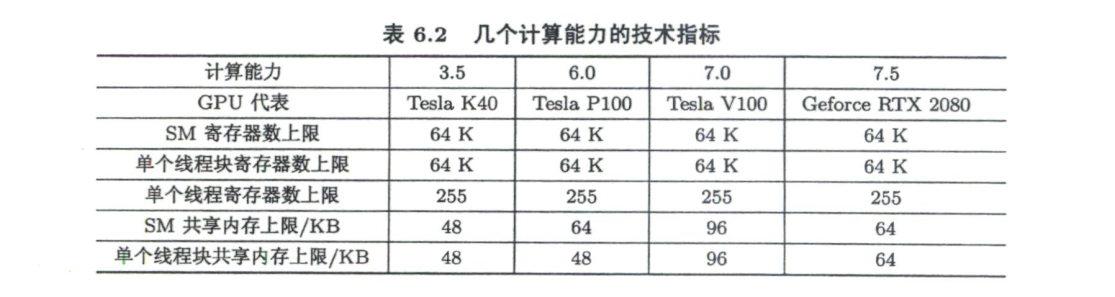
SM及其占有率
SM的构成
一个GPU由多个SM构成,一个SM包括如下资源:
- 一定数量的寄存器
- 一定数量的共享内存
- 常量内存的缓存
- 纹理和表面内存的缓存
- L1缓存
- 两个(计算能力6.0)或4个(其他计算能力)线程束调度器,用于在不同线程的上下文之间迅速地切换,以及为准备就绪的线程束发出执行指令。
- 执行核心,包括:
- 若干整型数运算的核心(INT32)
- 若干单精度浮点数运算核心(FP32)
- 若干双精度浮点数运算核心(FP64)
- 若干单精度浮点数超越函数的特殊函数单元(?)
- 若干混合精度的张量核心
SM的占有率
要分析SM的理论占有率,还需要知道两个指标:
- 一个SM中最多能拥有的线程块个数为Nb=16(开普勒架构和图灵架构)或者Nb=32(麦克斯韦架构、帕斯卡架构和伏特架构)。
- 一个SM中最多能拥有的线程个数为Nt≡2048(从开普勒架构到伏特架构)或者Nt=1024(图灵架构)。
SM中线程的执行是以线程束为单位的,所以最好将线程块大小取为线程束大小(32个线程)的整数倍
分几种情况进行分析:
寄存器和共享内存使用量很少的情况
在该前提下,任何不小于Nt / Nb而且能整除Nt的线程块大小都能得到100%的占有率。
有限的寄存器数量对占有率的约束情况
对于表6.2中列出的所有计算能力,一个SM最多能使用的寄存器个数为64K(64×1024)。除图灵架构外,如果我们希望在一个SM中驻留最多的线程(2048个),核函数中的每个线程最多只能用32个寄存器。当每个线程所用寄存器个数大于64时,SM的占有率将小于50%;当每个线程所用寄存器个数大于128时,SM的占有率将小于25%。
对于图灵架构,同样的占有率允许使用更多的寄存器。
有限的共享内存对占有率的约束情况
针对计算能力3.5来说,。如果线程块大小为128,那么每个SM要激活16个线程块才能有2048个线程,达到100%的占有率。此时,—个线程块最多能使用3KB的共享内存。在不改变线程块大小的情况下,要达到50%的占有率,一个线程块最多能使用6KB的共享内存。要达到25%的占有率,一个线程块最多能使用12KB的共享内存。如果—个线程块使用了超过48KB的共享内存,会直接导致核函数无法运行。
使用CUDA工具NVIDIA Nsight Compute 可对SM占用率进行分析
编译器选项--ptxas-options=-v可以报道每个核函数的寄存器使用数量。使用此选项对数组相加程序进行编译,得到如下结果
1 | ptxas info : 0 bytes gmem |
CUDA还提供了核函数的__launch_bounds__()修饰符和--maxrregcount=编译选项来让用户分别对—个核函数和所有核函数中寄存器的使用数量进行控制。
使用CUDA运行时API获取设备信息
程序见 query.cu 结果如下:
1 | Device id: 0 |