CUDA编程01: 一个简单的CUDA C++程序
这一系列笔记主要参考樊哲勇《CUDA编程:基础与实践》。
测试下面的代码使用的电脑配置为:
- i7-9700F
- GeForce RTX 2070SUPER
编程环境:
- Ubuntu 20.04 LTS
- nvcc 10.2
概述
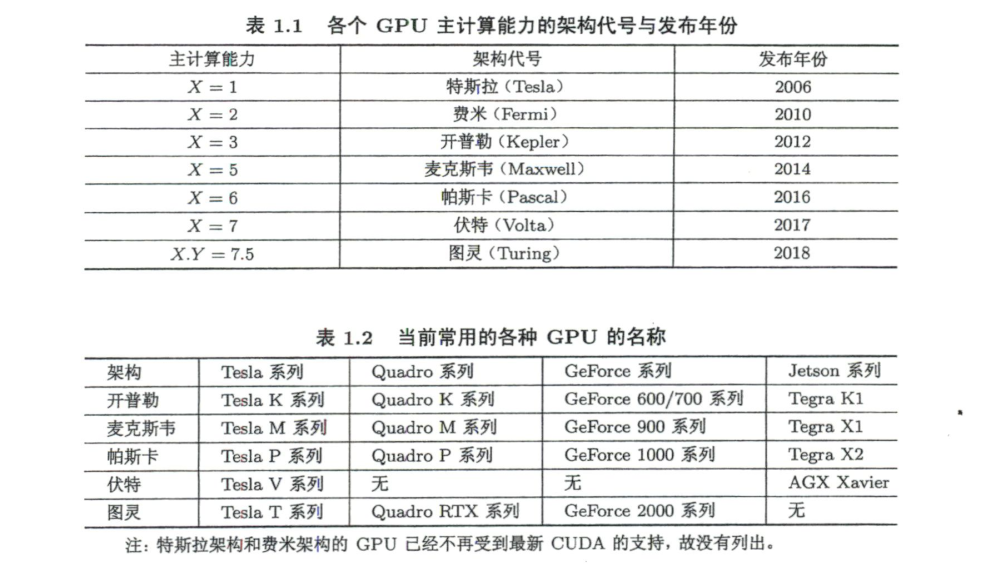
- 数据相关性是限制并行性的一个主要因素
- Tesla系列显卡提供内存纠错,适用于高性能高强度科学计算
- Quadro系列支持高速OpenGL渲染,用于专业绘图设计
- GeForce用于游戏与娱乐
CUDA Hello world程序
一个最简单的CUDA程序结构如:
1 | int main() { |
下面是一个CUDA Hello World程序,其中还演示了类方法调用核函数
1 |
|
输出如下信息:
1 | Hello from CPU |
对上述函数的一些说明:
- 核函数使用
__global__修饰 - 核函数返回值类型必须为
void __global__和void可互换位置- 对
<<<1, 10>>>的解释:- 主机在调用一个核函数时,必须指明需要在设备中指派多少个线程
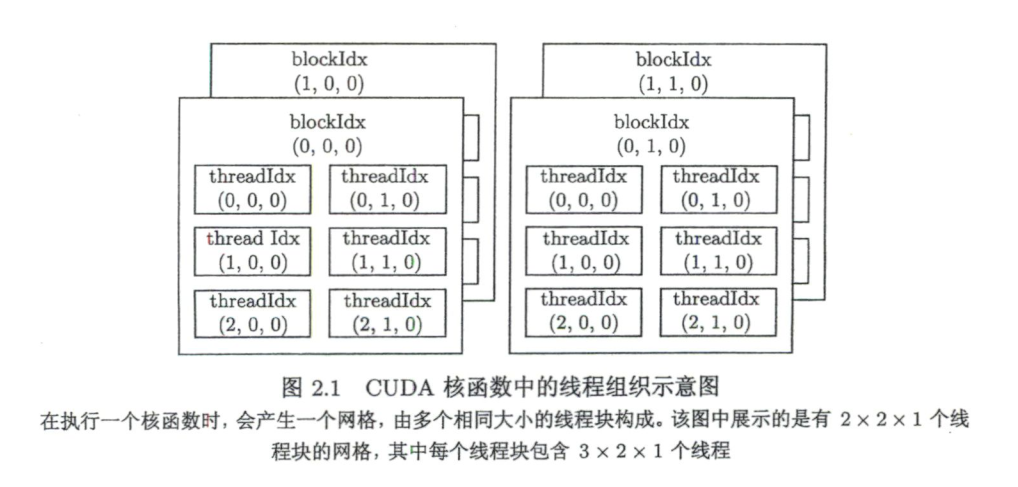
- 核函数中的线程常组织为若干线程块(thread block)
- 三括号中的第一个数字可以看作线程块的个数,第二个数字可以看作每个线程块中的线程数
- 一个核函数的全部线程块构成—个网格(grid)
- 而线程块的个数就记为网格大小(grid size)
- 每个线程块中含有同样数目的线程,该数目称为线程块大小(block size)
- 所以核函数中总的线程数就等于网格大小乘以线程块大小
- 从另一个角度来说,三括号中的两个数字分别为网格大小和线程块大小,即
<<<网格大小, 线程块大小>>>
cudaDeviceSynchronize()用来刷新缓冲区,并同步主机与设备cudaDeviceReset()也可以达到这样目的。
CUDA函数內建了一些变量,比如如下的程序:
1 |
|
输出结果为:
1 | Grid size 2, block size 4. Hello from block 1 and thread 0! |
gridDim.x: 该变量的数值等于执行配置中变量grid_size的数值blockDim.x: 该变量的数值等于执行配置中变量block_size的数值blockIdx.x: 该变量指定一个线程在一个网格中的线程块指标,其取值范围是从0到gridDim.x - 1threadIdx.x: 该变量指定一个线程在一个线程块中的线程指标,其取值范围是从0到blockDim.x - 1
多维网格
<<<grid_size, block_size>>>中的grid_size和block_size是类型为dim3的变量, dim3是一个结构体,具有x, y, z三个成员,未指定的默认为1。blockIdx和threadIdx是类型为unit3的变量,也是结构体,具有x, y, z三个成员。
可以用相应的构造函数构造多维网格:
1 | dim3 grid_size(2, 2); |
定义了如下网格:
网格与线程块大小的限制
任何从开普勒到图灵架构的GPU来说:
- 网格大小在x, y和z这3个方向的最大允许值分别为231-1、65535和65535
- 线程块大小在x, y和z这3个方向的最大允许值分别为1024、1024和64
- 另外,还要求线程块总的大小,即
blockDim.x,blockDim.y和blockDim.z的乘积不能大于1024
CUDA程序基本框架
一个典型的CUDA程序基本框架如下:
1 | 头文件包含 |
下面是一个在GPU中进行两个数组按元素求和并判断结果是否正确的CUDA程序:
1 |
|
对上述程序进行一些解读:
当调用第一个GPU操作函数时(非版本查询、设备管理等函数)GPU将自动初始化
cudaMalloc()函数原型为1
cudaError_t cudaMalloc(void **address, size_t size);
- 我们要改变主机指针的数值到设备上,所以传入的是指针的指针
size是字节数,而不是MPI中的count- 返回值是一个错误代码
cudaMemcpy()原型为1
2
3
4
5
6cudaError_t cudaMemcpy (
void * dst,
const void * src,
size_t count,
enum cudaMemcpyKind kind
)count是字节数,而不是MPI中的countkind有效取值包括cudaMemcpyHostToHostcudaMemcpyHostToDevicecudaMemcpyDeviceToHostcudaMemcpyDeviceToDevicecudaMemcpyDefault,这个取值会自动判断数据流向
核函数不支持可变数量的参数列表
上个代码中数组元素个数N正好可以被block_size整除,如果N无法被整除,可以使用int grid_size = (N - 1) / block_size + 1或者int grid_size = (N + block_size - 1) / block_size。这两个语句都等价于
1 | int grid_size = N % block_size == 0? N / block_size : N / block_size + 1 |
自定义设备函数
设备函数是在设备中被调用,在设备中执行的函数
__global__修饰的是核函数,主机调用,设备执行__device__修饰的是设备函数,在设备中调用,设备中执行,可以有返回值__host__修饰主机普通的C++函数,主机调用,主机执行,可省略。但__host__和__device__可以同时修饰一个函数,编译器将分别编译- 不能同时使用
__device__和__global__,不能同时使用__host__和__global__ - 设备函数可以内联或非内联,由编译器决定。可以使用
__noinline__建议非内联(编译器不一定会接受),也可以__forceinline__建议内联
对上述数组元素相加程序,可以将设备中的相加操作定义为设备函数,可以有返回值
1 | double __device__ add_element(const double x, const double y) { |
也可以用指针
1 | void __device__ add_element(const double x, const double y, double *z) { |
还可以用引用
1 | void __device__ add_element(const double x, const double y, double &z) { |
CUDA程序错误检测
CUDA API函数错误检测
CUDA一些运行时API函数会返回一个类型为cudaError_t的返回值,只有返回cudaSucess时才算执行成功。因此我们可以创建一个头文件error.cuh并定义一个宏用来检测运行期错误:
1 |
cudaGetErrorString(error_code)用于将错误代号转换成文字
在之前的程序中,包含error.cuh之后,将所有CUDA函数使用CHECK()包装,比如
1 | CHECK(cudaMalloc((void **)&d_x, M)); |
为了测试错误代码,将函数cudaMemcpy(d_x, h_x, M, cudaMemcpyHostToDevice)的最后一个参数(数据流向)反转,即
1 | CHECK(cudaMemcpy(d_x, h_x, M, cudaMemcpyDeviceToHost)); |
编译并执行后,得到如下结果:
1 | CUDA Error: |
核函数错误检测
因为核函数无返回值,所以无法使用上述办法进行错误检测,不过可以在核函数调用后增加如下两行:
1 | CHECK(cudaGetLastError()); |
第一条语句捕捉最后一个错误,第二条用来同步,因为核函数调用是异步的。我们在上述程序中将block_size修改为1280(block size不能大于1024),即
1 | const int block_size = 1280; |
会得到如下错误信息:
1 | CUDA Error: |
注意,上述程序中即使不使用CHECK(cudaDeviceSynchronize())也可正常检测出错误,是因为下面的数据拷贝函数隐式进行了同步。
更改环境变量
export CUDA_LAUNCH_BLOCKING=1将所有核函数的调用设置为同步的
内存错误检测
使用命令
1 | cuda-memcheck app_name |
使用CUDA事件计时
CUDA提供了基于CUDA事件的计时方式。
从本节开始,使用条件编译方式选择浮点数精度,在程序开头部分有:
1 |
|
使用CUDA事件对C++程序计时
在函数add前后使用计时:
1 | cudaEvent_t start, stop; |
完整代码见 addCPU_event.cu
对如上程序的几点说明:
cudaEventQuery(start)不能使用CHECK宏,因为cudaEventQuery(start)很有可能返回cudaErrorNotReady,但又不代表程序出错了- 统计时间时,一共调用了11次,但是第1次调用,机器可能处于预热状态,结果不准确,所以没有统计
- 如果想使用双精度,编译时添加
-DUSE_DP选项 - 编译时使用了
-O3优化选项
使用单精度时,运行结果如下
1 | Trial 0: time = 102.335 ms. |
使用CUDA事件对CUDA程序计时
主要修改的部分与C++程序几乎一样,完整代码见 addGPU_event.cu
使用单精度时,运行结果如下
1 | Trial 0: time = 2.98701 ms. |
结果分析
原书作者用上述程序测试了一系列显卡,结果如下
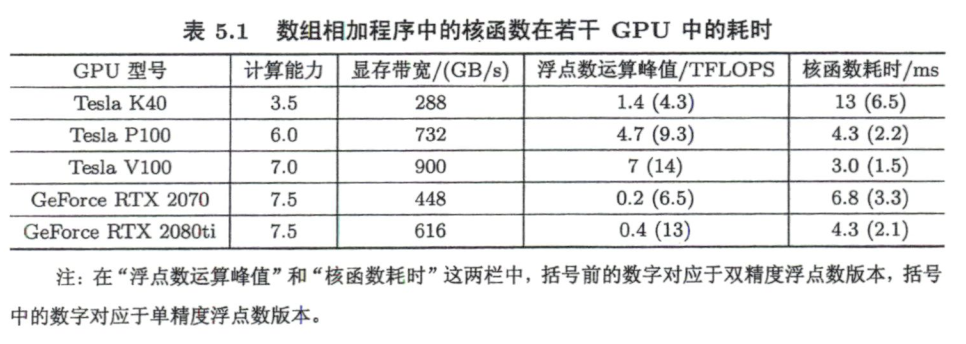
我的2070SUPER显存带宽与2070相同
从表5.1中可以看出,该比值与单、双精度浮点数运算峰值的比值没有关系。这是因为,对于数组相加的问题,其执行速度是由显存带宽决定的,而不是由浮点数运算峰值决定的。
有效显存带宽定义为GPU在单位时间内访问设备内存的字节。那么上述结果计算得到的显存带宽为
可以看出有效带宽未达到理论带宽,说明是访存主导的。注意,上面公式中分子的3表示执行了三个变量的访存操作
我们仅对核函数进行了计时,并未对数据复制函数计时。如果将数据复制加入被计时的代码,可以得到如下结果
1 | Trial 0: time = 212.903 ms. |
可以看出还没有CPU省时。完整程序见 addGPU_eventmemcpy.cu
使用nvprof进行性能剖析
1 | nvprof ./build/addGPU_eventmemcpy_float |
得到结果如下
1 | Type Time(%) Time Calls Avg Min Max Name |
可以看出大于97%的时间用在了数据复制上。
影响GPU加速的关键因素
数据传输的比例
GPU计算核心和设备内存之间数据传输的理论带宽要远高于GPU和CPU之间数据传输的带宽。应避免过多数据经由PICe传递
算数强度
—个计算问题的算术强度指的是其中算术操作的工作量与必要的内存操作的工作量之比。提高算术强度能够显著地提高GPU相对于CPU的加速比。
并行规模
并行规模可用GPU中总的线程数目来衡量。从硬件的角度来看,一个GPU由多个流多处理器SM构成,而每个SM中有若干CUDA核心。每个SM是相对独立的。对于图灵架构,一个SM中最多能驻留的线程个数是1024。一块GPU中—般有几个到几十个SM。所以一块GPU一共可以驻留几万到几十万个线程。如果一个核函数中定义的线程数目远小于这个数的话,就很难得到很高的加速比。
CUDA中的数学函数库
- 数学函数:经过重载,精度较高
1
2
3double sqrt(double x);
float sqrt(float x);
float sqrtf(float x); - 内建函数:效率较高,准确性较低
1
2
3
4float __fsqrt_rd(float x); // round-down mode
float __fsqrt_rn(float x); // round-to-nearest-even mode
float __fsqrt_ru(float x); // round-up mode
float __fsqrt_rz(float x); // round-towards-zero mode